It’s very interesting (and well, a bit suspicious) that the main focus of most VoLTE textbooks and trainings is signalling. But from the user-point-of-view, it is the voice data, what matters. As an end-subscriber I don’t care about signalling. My only interest is the call quality. But times they are a changin and engineers are asking about how to improve the overall voice-call quality and user experience. Today we’ll go through the basics as jitter, mouth-to-ear delay, packet loss rate or MOS, needed for QoS analysis.
For real-time multimedia we used to have dedicated telephone/radio networks. That has changed and voice/video streams are transported over IP network now.
We should understand that these IP networks were originally designed for data transport. To transport data we prefer the best-effort service model, which allows an easy network scaling and simple routers’ logic. On the other hand we don’t care much if packets arrive in-order or what are the delays between particular packets. We simply wait until we receive a whole file. If any packet is lost, TCP will re-transmit it.

Packets in Data Networks
It’s a different story with the real-time communication services though. RTC applications are less sensitive to packet loss, but they are very sensitive to packet delay. Usage of IP data network as a carrier brings a lot of challenges which have to be addressed by media protocols and network elements.
Voice Call Quality
Let’s start with some basic definitions and facts.
• Latency (Packet Delay Budget)
Latency (also known as mouth-to-ear delay or just delay) represents the time which it takes a voice packet to reach its destination. Latency is measured in milliseconds (ms). Latency greater than 150 ms noticeably affects the call quality experience. More in detail described in ITU-T G.114.

Voice Call Latency
• Jitter
Jitter is defined as the variation in delay of packet arrival times. Simply put, we want to receive the packets within the same interval. E.g. because of network congestion, timing drift, or route changes the interval can variate and we experience following issues:
- We haven’t received the next packet in time, so we have no media to play. This can be solved by Jitter Buffer (3GPP TS 26.114). However buffering is increasing the Latency. Therefore the size of the buffer has to stay as minimal.
- We have received too many packets. If the the buffer isn’t big enough , it may happen the some packets are dropped.
Ideally all the packets should arrive with the same Latency. If the delay is long, the user experience is a little worst, but we don’t loose any information. But if the latency is unsteady == higher jitter, then some data is lost.

Jitter
Jitter is measured in milliseconds (ms). Jitter greater than 30 ms may result in packet drops which then impacts the call-quality.
• Packet Loss (Pacet Error Loss)
Packet loss typically occurs when some packets are dropped by congested network routers or switches. Or, as we have seen, packet can be also discarded by the jitter buffer. If any packet is lost, in contrast to data, we can’t wait for re-transmission (because of latency). If the number of lost packets stays reasonably low, there is only negligable impact on the call quality. With the higher amount of missing packets obviously the effects of packet loss may result in loss of syllables or even missing words during a conversation. More in detail in ITU-T G.113.
VoLTE defines the requirements for voice call latency as 100ms or less (one-way), VoLTE video latency as 150 ms or less. The Packet loss has to be less than 10-2 for voice and 10-3 for video. More information can be found in OTT and VoLTE Calls or VoLTE Policy Control Summary posts.
QoS Tools
Basic tools are embedded in most of the soft clients these days.

Soft Phone Stats
If that is not an option, we can get some idea about Latency, Jitter and Packet Loss, using the simplest tool – the ping command.

Jitter Readings from ping
In our example the average Latency is roughly 28/2 = 14 ms, max jitter cca (38 – 24)/2 = 7 ms. Btw. don’t forget to change the packet size.
Some better info can be provided by iperf command.
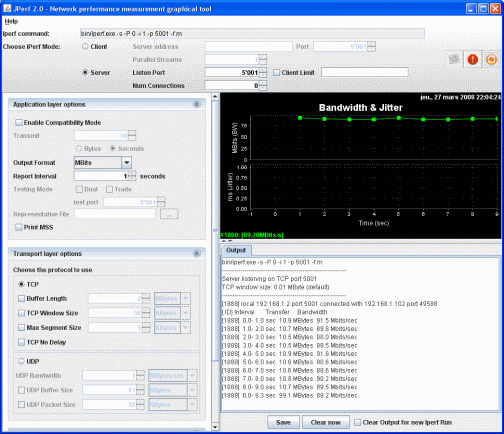
jperf
To analyse a call trace we can use Wireshark.

RTP Streams in Wireshark
To get RTP statistics you can simple select Telephony/RTP/RTP Streams. Then select your stream and press Analyze.

QoS Analysis in Wireshark
If you don’t have your own traces yet, you can easily use some from the Wireshark public repository.
To play with WebRTC you can try chrome://webrtc-internals/. Howto understand this tool can be found here.

webrtc-internals qos analysis
Listening Quality & MOS Scores
To measure the real voice-call quality is not an easy thing. What can be an acceptable call quality for someone, can be poor for someone else. ITU uses so-called Absolute Category Rating (ACR), where a pool of listeners rates the quality of audio files using a scores range from 1 to 5:
5 Excellent
4 Good
3 Fair
2 Poor
1 Bad
Then a Mean Opinion Score (MOS) for each audio file is calculated. Based on the use-case we distinguish MOS-Listening Quality (MOS-LQ) and MOS-Conversational Quality (MOS-CQ) with the additional suffixes (S)ubjective, (O)bjective and (E)stimated. E.g., a listening quality score measured by an ACR test is called a MOS-LQS. MOS-LQSW provides the MOS-LQS in Wide-Band (WB) context. (See ITU P.800.1 for details.)
For an ACR Test, a larger pool of people should be used (16 or more). Also the test should be done under controlled conditions in a quiet environment. ITU and the Open Speech Repository are sources of phonetically balanced speech material. The methodology on how to compare general ACR and ITU ratings, WB and NB scores, etc. is quite complex, more in depth it is described e.g. in Integral and Diagnostic Intrusive Prediction of Speech Quality By Nicolas Côté.
R-Factor
The overall call quality is affected by many transmission parameters that are combined together and have to be taken into account. Therefore it is very difficult to truly understand the contribution of each individual parameter (e.g. Mean Delay, Weighted Echo Path Loss, Receive Loudness Rating, …). The E-Model is a computational model which provides a scalar quality rating value, R. This Factor R corresponds directly with the overall conversational quality. The E-Model is defined in ITU-T Rec. G.107 and can be used as a powerful transmission planning tool providing a prediction of the expected voice quality.
Factor R is an alternative method of assessing call quality you can often see as a part of call statistics. The following table demonstrates the effect of the MOS and R-Factor on the perceived call quality.
| R-value (lower limit) |
MOSCQE (lower limit) |
User satisfaction |
| 90 | 4.34 | Very satisfied |
| 80 | 4.03 | Satisfied |
| 70 | 3.6 | Some users dissatisfied |
| 60 | 3.1 | Many users dissatisfied |
| 50 | 2.58 | Nearly all users dissatisfied |
VoLTE Media
VoLTE media capabilities are specified in 3GPP TS 26.114. The document contains the description for UEs and for entities in the IMS core network that terminate the user plane. ITU-T G.1028 then gives us some guidance for various types of service:
Quality budgets for LTE-LTE communication on the same network
| End-to-end indicators | TOTAL budget | Terminal | EUTRAN | EPC | Mobile IMS | Transmission network |
| Registration success rate | 99.90% | 99.90% | 99.90% | 100.00% | 99.90% | – |
| Service availability | 99% Note 1 |
– | – | – | – | – |
| Post dialling delay (PDD) | LTE-LTE: 3.5 s Note 2 |
– | – | – | – | – |
| Mouth-to-ear delay | 400 ms Note 5 |
190 ms (sending + receiving) Note 6 |
80 ms on both sides |
50 ms | 0 | 10 ms (may be bigger for large countries) |
| Call drop rate | 2% | – | – | – | – | – |
NOTE 1 – Call processing performance objective according to ETSI TS 101.563 is higher than 99.9%.
NOTE 2 – ETSI TS 101.563 recommends 5.9 s, with 95% of probability below 2.4 s.
NOTE 3 – Only circuit switched fall back on mobile originating side is considered here.
NOTE 5 – ITU-T G.114 specifies a preferred maximum value at 150 ms, impossible to reach currently;
some network operators are able to provide national calls with delays below 250 ms.
NOTE 6 – According to 3GPP TS 26.131
The overall voice-call quality also depends on what technologies are involved or if more operators are interworking.
Voice quality based on call flow
| LTE-LTE | LTE-LTE interconnected |
LTE – 3G | LTE-PSTN | |
| Latency | 400 ms | 400 ms | 400 ms | 400 ms |
| Drop Rate | 2% | 2% | 3% | 2% |
| Voice quality (MOS-LQSW) | 4 | 4 if HD + TrFO 2.8 otherwise |
3.8 | 3.1 |
VoLTE Codecs
I bet you have heard that Codecs (the actual RTP payload) have something to do with the voice quality too. If you’re interested you maybe even heard about Codec Wars. Surely the chosen way of media encoding determines the final quality and the needed bandwidth.
GSMA PRD IR.92 has mandated AMR / AMR-WB codecs to be used for VoLTE. These codecs have to be implemented by all equipment manufactures to ensure a good voice quality as well as facilitating inter-operability and avoiding transcoding. Other voice codecs can be also supported by operators in addition to the AMR codecs.
- The UE must support the AMR, including all 8 modes and source rate controlled operations (3GPP TS 26.093). Moreover the UE has to be capable of operating with any subset of these eight codec modes.
- The UE must support AMR-WB including all nine modes and source controlled rate operation (3GPP TS 26.193). Again the UE has to be capable of operating with any subset of these nine codec modes.
- If the EVS codec is supported, then the EVS AMR-WB IO mode may be used as an alternative implementation of AMR-WB.
- If super-wideband or fullband speech communication is offered, then the UE must support the EVS codec.
More information in VoLTE close encounters.
In contrast to VoLTE in VoIP (Enterprise), we use many more codecs. Therefore we have to often deal with transcoding and transrating. Transcoding usually degrades the voice quality e.g G722<->AMR-WB transcoding causes degradation 0.2 to 0.4 MOS-LQSW below G.722 64. More info you can find Quality comparison of wideband coders including tandeming and transcoding.
Start now!
We should have enough information to start playing with the media setting. To get a bit more practical experience check yourselves and listen to various samples & codecs!
Where to go next?
- OTT and VoLTE Calls
- VoLTE Policy Control Summary
- http://www.voiptroubleshooter.com/diagnosis/index.html
Did you enjoy the reading? Let us know!
